
DataRobot is an AI and machine learning platform that simplifies the process of building, deploying, and maintaining machine learning models. It offers tools to automate many of the tasks involved in these processes. This article will guide you through using DataRobot in Python, covering everything from installation to building and deploying models.
What is DataRobot?
DataRobot is a platform that helps data scientists and analysts build and deploy machine learning models. It provides automated machine learning (AutoML) capabilities, making it easier to create models without extensive coding. DataRobot supports a wide range of machine learning algorithms and can handle various data types and problem domains.
Getting Started with DataRobot in Python
Prerequisites
Before you start using DataRobot in Python, ensure you have the following:
- A DataRobot account. (If you don’t have an account create one)
- Python installed on your system.
- Basic knowledge of Python and machine learning concepts.
Installation
To use DataRobot with Python, you need to install the datarobot package. You can do this using pip, Python’s package installer. Open your terminal or command prompt and run the following command:
pip install datarobot
This will install the DataRobot Python client library.
Setting Up
To use DataRobot, you need to authenticate using an API key. You can find your API key in your DataRobot account settings. Once you have your API key, you can set it up in your Python environment.
Create a file named datarobot_config.py and add the following code to it:
import datarobot as dr
API_KEY = 'your_api_key_here'
dr.Client(token=API_KEY)
Replace 'your_api_key_here' with your actual API key. This script will authenticate your connection to DataRobot.
Importing Data
To build a machine learning model, you first need to import your data. DataRobot can handle various data formats, including CSV, Excel, and databases. For this example, we’ll use a CSV file.
Let’s say you have a CSV file named data.csv. You can upload this file to DataRobot using the following code:
import datarobot as dr
# Load your CSV file
dataset_path = 'data.csv'
# Upload the dataset to DataRobot
dataset = dr.Dataset.create_from_file(dataset_path)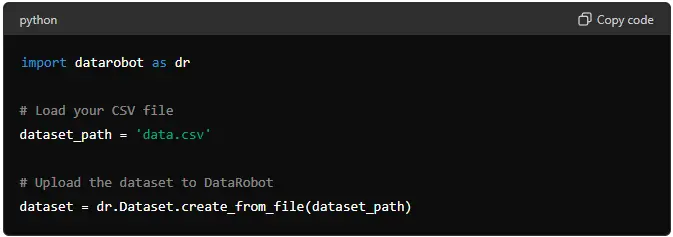
This code uploads your CSV file to DataRobot and creates a dataset object.
Exploring the Data
Before building a model, it’s a good idea to explore your data. DataRobot provides several methods to understand your dataset.
# Get dataset information
dataset_info = dataset.get_info()
print(dataset_info)
# Get dataset statistics
dataset_stats = dataset.get_stats()
print(dataset_stats)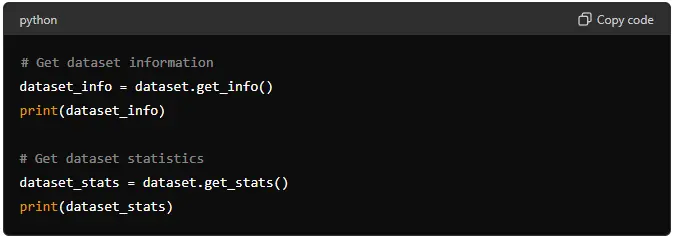
These methods provide information about your dataset, such as the number of rows and columns, data types, and summary statistics.
Building a Model
Once your data is uploaded and explored, you can start building a machine learning model. DataRobot automates much of this process, making it simple to create and compare multiple models.
# Define the target variable
target = 'your_target_variable'
# Start a modeling project
project = dr.Project.start(project_name='My Project', dataset_id=dataset.id, target=target)
# Wait for the project to complete initial processing
project.wait_for_autopilot()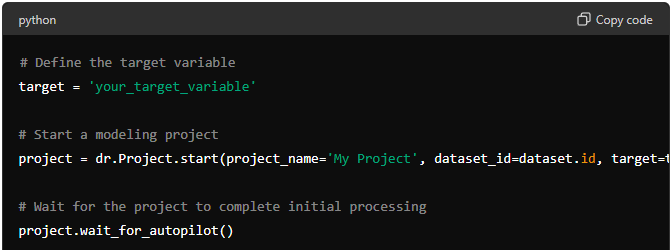
Replace 'your_target_variable' with the name of the column you want to predict. This code creates a new modeling project and starts the AutoML process.
Evaluating Models
After the AutoML process is complete, DataRobot will have built several models. You can evaluate these models to find the best one.
# Get the list of models
models = project.get_models()
# Print model summaries
for model in models:
print(f"Model ID: {model.id}, Model Type: {model.model_type}, Accuracy: {model.metrics['accuracy']['value']}")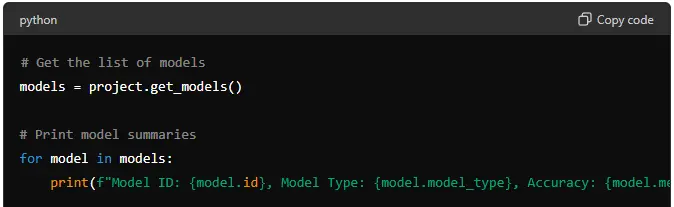
This code retrieves the list of models and prints a summary of each one, including its ID, type, and accuracy.
Selecting the Best Model
To select the best model, you can sort the models based on a specific metric. For example, to select the model with the highest accuracy, you can do the following:
# Sort models by accuracy
sorted_models = sorted(models, key=lambda x: x.metrics['accuracy']['value'], reverse=True)
# Select the best model
best_model = sorted_models[0]
print(f"Best Model ID: {best_model.id}, Accuracy: {best_model.metrics['accuracy']['value']}")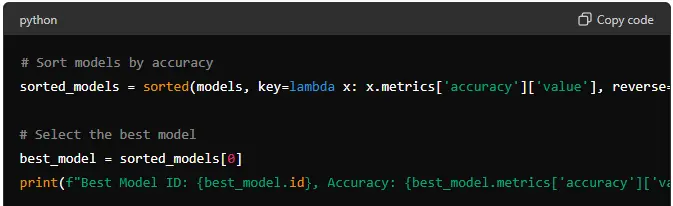
This code sorts the models by accuracy and selects the one with the highest value.
Making Predictions
Once you have selected the best model, you can use it to make predictions on new data. First, you need to upload the new data to DataRobot.
# Load new data for predictions
new_data_path = 'new_data.csv'
# Upload the new data
new_dataset = dr.Dataset.create_from_file(new_data_path)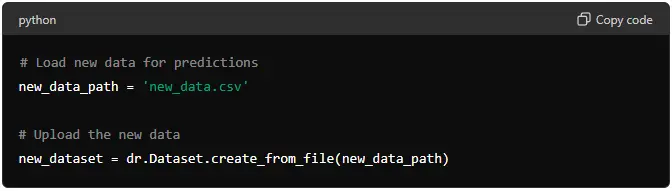
Next, you can use the model to make predictions on the new data.
# Make predictions
predictions = best_model.predict(new_dataset.id)
# Print predictions
print(predictions)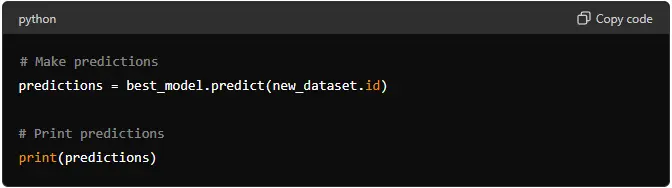
This code uploads the new data and uses the selected model to make predictions.
Deploying the Model
DataRobot makes it easy to deploy your models, allowing you to integrate them into your applications. You can deploy a model with a few lines of code.
# Deploy the model
deployment = dr.Deployment.create(model_id=best_model.id, label='My Deployment')
# Get deployment information
deployment_info = deployment.get_info()
print(deployment_info)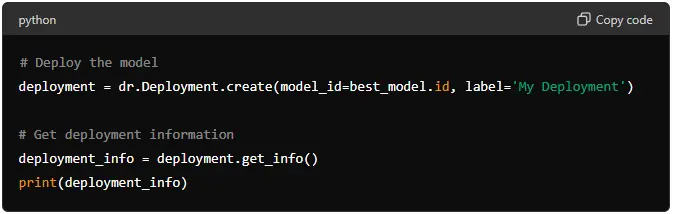
This code deploys the selected model and prints the deployment information.
Monitoring the Deployment
Once your model is deployed, it’s important to monitor its performance. DataRobot provides tools to track your model’s performance over time.
# Get deployment status
deployment_status = deployment.get_status()
print(deployment_status)
# Get deployment metrics
deployment_metrics = deployment.get_metrics()
print(deployment_metrics)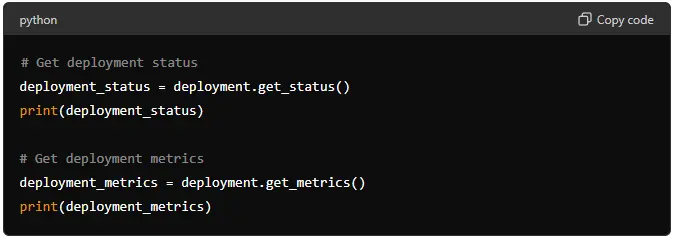
These methods provide information about your deployment’s status and performance metrics.
Updating the Model
As new data becomes available, you may need to update your model. DataRobot makes it easy to retrain and redeploy your models.
# Load new training data
new_training_data_path = 'new_training_data.csv'
# Upload the new training data
new_training_dataset = dr.Dataset.create_from_file(new_training_data_path)
# Start a new modeling project with the updated data
new_project = dr.Project.start(project_name='Updated Project', dataset_id=new_training_dataset.id, target=target)
# Wait for the project to complete initial processing
new_project.wait_for_autopilot()
# Select the best model from the new project
new_models = new_project.get_models()
new_best_model = sorted(new_models, key=lambda x: x.metrics['accuracy']['value'], reverse=True)[0]
# Update the deployment with the new model
deployment.update_model(new_best_model.id)
# Get updated deployment information
updated_deployment_info = deployment.get_info()
print(updated_deployment_info)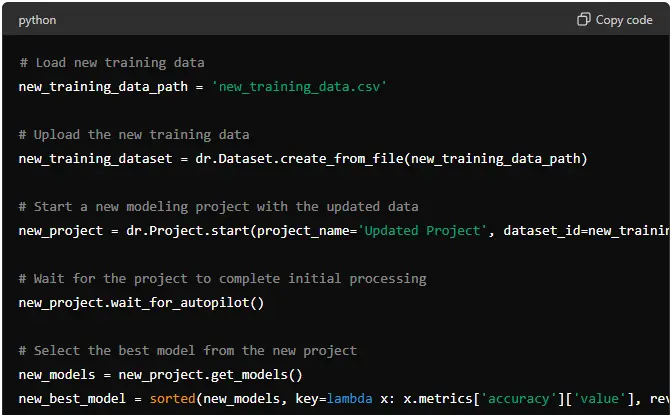
This code uploads new training data, creates a new modeling project, and updates the deployment with the best model from the new project.
Conclusion
DataRobot simplifies the process of building, deploying, and maintaining machine learning models. With its AutoML capabilities, you can quickly create and compare multiple models, select the best one, and deploy it with ease. The DataRobot Python client library makes it easy to integrate these capabilities into your Python applications.
By following the steps outlined in this article, you can get started with DataRobot in Python, from installation and data import to model building, deployment, and monitoring. Whether you’re a data scientist, analyst, or developer, DataRobot provides the tools you need to harness the power of machine learning.
FAQs : Datarobot in python
What is DataRobot and what does it do?
DataRobot is an AI and machine learning platform that automates the process of building, deploying, and maintaining machine learning models. It offers tools to create models quickly and efficiently without extensive coding knowledge, supporting a wide range of machine learning algorithms and data types.
How do I install the DataRobot Python client?
You can install the DataRobot Python client using pip, the Python package installer. Open your terminal or command prompt and run the following command:
python
pip install datarobot
This will install the necessary library to use DataRobot with Python.
How do I authenticate my connection to DataRobot in Python?
To authenticate your connection, you need an API key from your DataRobot account. Create a file named datarobot_config.py and add the following code, replacing 'your_api_key_here' with your actual API key:
python
import datarobot as dr
API_KEY = ‘your_api_key_here’
dr.Client(token=API_KEY)
How can I upload data to DataRobot?
To upload a CSV file to DataRobot
you can use the following code snippet:
python
import datarobot as dr
# Load your CSV file
dataset_path = ‘data.csv’
# Upload the dataset to DataRobot
dataset = dr.Dataset.create_from_file(dataset_path)
This code uploads your CSV file to DataRobot and creates a dataset object.
How do I start a modeling project in DataRobot?
To start a modeling project, you need to define the target variable you want to predict. Use the following code:
python
# Define the target variable
target = ‘your_target_variable’
# Start a modeling project
project = dr.Project.start(project_name=’My Project’, dataset_id=dataset.id, target=target)
# Wait for the project to complete initial processing
project.wait_for_autopilot()
Replace 'your_target_variable' with the name of the column you want to predict.
How do I evaluate models in DataRobot?
After the AutoML process is complete, you can evaluate the models by retrieving and printing their summaries:
python
# Get the list of models
models = project.get_models()
# Print model summaries for model in models:
print(f”Model ID: {model.id}, Model Type: {model.model_type}, Accuracy: {model.metrics[‘accuracy’][‘value’]}”)
How do I select the best model in DataRobot?
To select the best model based on a specific metric like accuracy, you can sort the models and select the one with the highest accuracy:
python
# Sort models by accuracy
sorted_models = sorted(models, key=lambda x: x.metrics[‘accuracy’][‘value’], reverse=True)
# Select the best model
best_model = sorted_models[0]
print(f”Best Model ID: {best_model.id}, Accuracy: {best_model.metrics[‘accuracy’][‘value’]}”)


